1.章节介绍
在爬虫项目当中,我们需要将目标站点数据数据进行持久化保存,一般数据保存的方式有两种:
- 文件保存
- 数据库保存
2. CSV文件存储
什么是csv
通俗直白的说:就是一个普通文件,里面的内容是每一行中的数据用逗号分隔,然后文件后缀为.csv
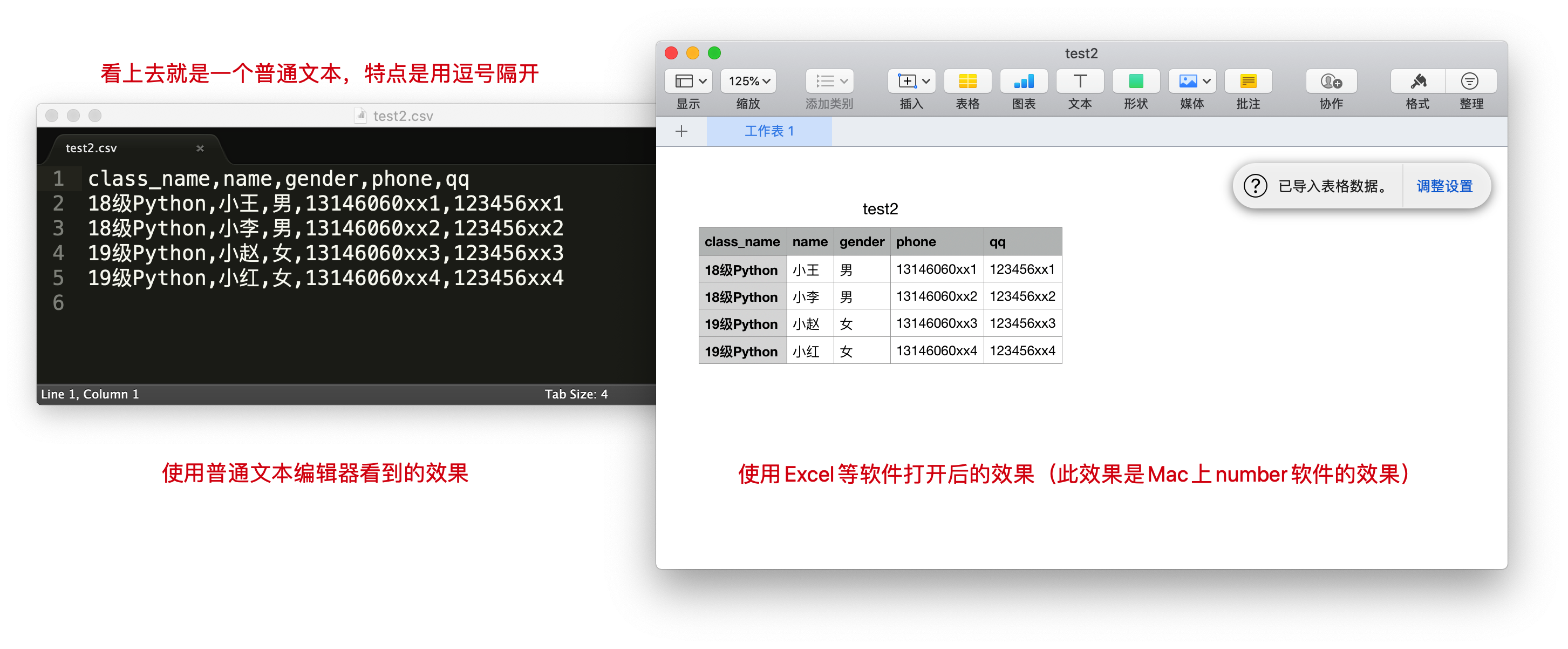
Python对csv文件进行读写操作
写入列表数据到
CSV文件
import csv
headers = ['班级', '姓名', '性别', '手机号', 'QQ']
rows = [
["18级Python", '小王', '男', '13146060xx1', '123456xx1'],
["18级Python", '小李', '男', '13146060xx2', '123456xx2'],
["19级Python", '小赵', '女', '13146060xx3', '123456xx3'],
["19级Python", '小红', '女', '13146060xx4', '123456xx4'],
]
with open('test_1.csv', 'w') as f:
# 创建一个csv的writer对象,这样才能够将写入csv格式数据到这个文件
f_csv = csv.writer(f)
# 写入一行(我们用第一行当做表头)
f_csv.writerow(headers)
# 写入多行(当做数据)
f_csv.writerows(rows)写入字典数据到
CSV文件
import csv
rows = [
{
"class_name": "18级Python",
"name": '小王',
"gender": '男',
"phone": '13146060xx1',
"qq": '123456xx1'
},
{
"class_name": "18级Python",
"name": '小李',
"gender": '男',
"phone": '13146060xx2',
"qq": '123456xx2'
},
{
"class_name": "19级Python",
"name": '小赵',
"gender": '女',
"phone": '13146060xx3',
"qq": '123456xx3'
},
{
"class_name": "19级Python",
"name": '小红',
"gender": '女',
"phone": '13146060xx4',
"qq": '123456xx4'
},
]
with open('test_2.csv', 'w') as f:
# 创建一个csv的DictWriter对象,这样才能够将写入csv格式数据到这个文件
f_csv = csv.DictWriter(f, ['class_name', 'name', 'gender', 'phone', 'qq'])
# 写入一行(我们用第一行当做表头)
f_csv.writeheader()
# 写入多行行(当做数据)
f_csv.writerows(rows)读取
CSV文件
import csv
with open('test_1.csv') as f:
# 创建一个reader对象,迭代时能够提取到每一行(包括表头)
f_csv = csv.reader(f)
for row in f_csv:
print(type(row), row)读取
CSV文件内容并封装为字典
import csv
with open('test_2.csv') as f:
# 创建一个reader对象,迭代时能够提取到每一行(包括表头)
f_csv = csv.DictReader(f)
for row in f_csv:
# print(type(row), row)
print(row.get("class_name"), row.get("name"), row.get("gender"), row.get("phone"), row.get("qq"))爬虫案例 - B站数据采集
import csv
import requests
class SaveVideoInfo:
def __init__(self):
self.api_url = 'https://api.bilibili.com/x/web-interface/wbi/search/type?context=&search_type=video&page={}&order=&keyword=%E7%BE%8E%E5%A5%B3&duration=&category_id=&tids_1=&tids_2=&__refresh__=true&_extra=&highlight=1&single_column=0&web_location=1430654&w_rid=3035c5c80e8a24b01a6685e0d276c5ff&wts=1698906392'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
'Cookie': "buvid3=24B2D828-680C-AC77-E787-13669953D2F063538infoc; b_nut=1697620963; i-wanna-go-back=-1; b_ut=7; _uuid=3FCB9672-AD35-B791-34EB-FBB394C1055DF61815infoc; enable_web_push=DISABLE; home_feed_column=5; buvid4=C4202519-7247-E9C8-E20C-E27302EDE53564679-023101817-STZcpyLLRzNibWQwQhkmXw%3D%3D; buvid_fp=77df88e74294ee94582ad08cb5f71cf4; CURRENT_FNVAL=4048; rpdid=|(kmJY|k~u~u0J'uYm~Yk|m)k; header_theme_version=CLOSE; SESSDATA=486a3b8a%2C1713507656%2C2602c%2Aa1CjADLWhb8hOljLOeLuedVVT6dmPfFDlTTryt7ZuXcTQacp6C-HeRFrNK59oZVhcUxtISVkRFWXNpNDhLbzZUUVNyT0xpNS1TaFJCYUx0NWQzNm4taDhva3hjM1EzTmZpc3Myc2gtdHZNTkNEYTFrdzZqSWxFcURoSjY1djZpVEN2V3JwaEFjdnBBIIEC; bili_jct=996967c0ccbec984e13ab8ccbfcf01cc; DedeUserID=508205460; DedeUserID__ckMd5=73fc57c2f075cc42; browser_resolution=1920-853; CURRENT_QUALITY=120; b_lsid=4D97C954_18B8EB2AAE2; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE2OTkxNjUzOTEsImlhdCI6MTY5ODkwNjEzMSwicGx0IjotMX0.NFeZiUClRc6JlUBJR0GFIPUKH4nY3fBqDZbOPGGsLgU; bili_ticket_expires=1699165331; sid=7i7fya69; PVID=2"
}
def save(self):
with open('video_info.csv', 'a', encoding='utf-8', newline='') as f:
field_names = ['author', 'arcurl', 'tag']
f_csv = csv.DictWriter(f, fieldnames=field_names)
f_csv.writeheader()
for page in range(1, 6):
response = requests.get(self.api_url.format(page), headers=self.headers).json()
for result in response['data']['result']:
item = dict()
item['author'] = result['author']
item['arcurl'] = result['arcurl']
item['tag'] = result['tag']
print(item)
f_csv.writerow(item)3. JSON文件存储
json数据格式介绍
JSON全称为JavaScript Object Notation, 也就是JavaScript对象标记,它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式。本节中,我们就来了解如何利用Python保存数据到JSON文件。
常见的json数据格式如下:
[
{
"name": "Bob",
"gender": "male",
"birthday": "1992-10-18"
},
{
"name": "Selina",
"gender": "female",
"birthday": "1995-10-18"
}
]由中括号包围的就相当于列表类型,列表中的每个元素可以是任意类型,这个示例中它是字典类型,由大括号包围。
JSON可以由以上两种形式自由组合而成,可以无限次嵌套,结构清晰,是数据交换的极佳方式。
Python中的json模块
| 方法 | 作用 |
|---|---|
json.dumps() | 把python对象转换成json对象,生成的是字符串。 |
json.dump() | 用于将dict类型的数据转成str,并写入到json文件中 |
json.loads() | 将json字符串解码成python对象 |
json.load() | 用于从json文件中读取数据。 |
爬虫案例 - 4399网站游戏信息采集
目标地址:https://www.4399.com/flash/
import json
import requests
from lxml import etree
url = 'https://www.4399.com/flash/'
response = requests.get(url)
html = etree.HTML(response.content.decode('gbk'))
a_list = html.xpath('//ul[@class="n-game cf"]/li/a')
data_list = []
for a in a_list:
item = dict()
item['href'] = a.xpath('./@href')[0]
item['title'] = a.xpath('./b/text()')[0]
data_list.append(item)
with open('data.json', 'w', encoding='utf-8') as f:
# f.write(json.dumps(data_list))
# 禁止ascii编码
f.write(json.dumps(data_list, indent=2, ensure_ascii=False))在写入过程中如果没有指定indent则写入的数据没有缩进,如果没有指定ensure_ascii参数则无法显示中文。
4.pymysql数据库存储
在大多数爬虫项目中,普遍还是将清洗后的数据存储到MySQL或者MongoDB中。接下来我们通过腾讯招聘岗位抓取案例来完成对数据的入库操作。
环境准备
在完成案例之前,我们需要做好准备工作:
安装
pymysqlpythonpip install pymysql -i https://pypi.douban.com/simple创建数据库
sqlcreate database py_spider charset=utf8;
代码示例
当前案例我们使用面向对象的方式,感兴趣的同学也可改写成函数的方式完成。
目标网站地址:https://careers.tencent.com/search.html?keyword=python&query=at_1
import pymysql
import requests
class TxWork:
url = 'https://careers.tencent.com/tencentcareer/api/post/Query?' \
'timestamp=1692878740516&countryId=&' \
'cityId=&bgIds=&productId=&categoryId=' \
'&parentCategoryId=&attrId=&' \
'keyword=python&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
def __init__(self):
self.db = pymysql.connect(host='localhost', user='root', password='root', db='py_spider')
self.cursor = self.db.cursor()
@classmethod
def get_work_info(cls):
for page in range(1, 46):
response = requests.get(cls.url.format(page), headers=cls.headers).json()
print(f'正在抓取第{page}页')
work_list = response['Data']['Posts']
yield work_list
def create_table(self):
sql = """
create table if not exists tx_work(
id int primary key auto_increment,
work_name varchar(100) not null,
country_name varchar(50),
city_name varchar(50),
work_desc text
);
"""
try:
self.cursor.execute(sql)
print('数据表创建成功...')
except Exception as e:
print('数据表创建失败: ', e)
def insert_work_info(self, *args):
"""
:param args:
id
work_name
country_name
city_name
work_desc
:return:
"""
sql = """
insert into tx_work(
id,
work_name,
country_name,
city_name,
work_desc
) values (%s, %s, %s, %s, %s);
"""
try:
self.cursor.execute(sql, args)
self.db.commit()
print('数据插入成功...')
except Exception as e:
print('数据插入失败: ', e)
self.db.rollback()
def main(self):
self.create_table()
all_work_generator_object = self.get_work_info()
work_id = 0
for work_info_list in all_work_generator_object:
for work_info in work_info_list:
print(work_info)
work_name = work_info['RecruitPostName']
country_name = work_info['CountryName']
city_name = work_info['LocationName']
work_desc = work_info['Responsibility']
self.insert_work_info(work_id, work_name, country_name, city_name, work_desc)
self.db.close()
if __name__ == '__main__':
tx_work = TxWork()
tx_work.main()作业
获取阿里招聘的岗位信息
地址:https://talent.taotian.com/off-campus/position-list?lang=zh
import pymysql
import requests
class ALiWork:
def __init__(self):
self.db = pymysql.connect(host='localhost', user='root', password='root', db='py_spider')
self.cursor = self.db.cursor()
self.api_url = 'https://talent.taotian.com/position/search?_csrf=051df885-fa9e-4443-afbf-d024967ba505'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
'Referer': 'https://talent.taotian.com/off-campus/position-list?lang=zh',
'Cookie': "cna=yny1HZ86bg8CAXH2a4H1B55y; xlly_s=1; prefered-lang=zh; XSRF-TOKEN=051df885-fa9e-4443-afbf-d024967ba505; SESSION=QjVCQjNCQkY3ODUzQ0FFN0U1Nzc3RjY4NUY3NUVBNzE=; isg=BAwM2yrDhRhU_5Fgv09xxtVC3Ww-RbDvTHBfWGbNYrcf8az7j1UHfwoAkflJuehH"
}
def get_work_info(self):
for page in range(1, 11):
json_data = {
"channel": "group_official_site",
"language": "zh",
"batchId": "",
"categories": "",
"deptCodes": [],
"key": "",
"pageIndex": page,
"pageSize": 10,
"regions": "",
"subCategories": ""
}
response = requests.post(self.api_url, headers=self.headers, json=json_data).json()
yield response['content']['datas']
def parse_work_info(self, response):
for work_info_list in response:
for work_info in work_info_list:
item = dict()
item['categories'] = work_info['categories'][0] if work_info['categories'] else '空'
item['work_name'] = work_info['name']
item['description'] = work_info['description']
print(item)
self.insert_work_info(0, item['categories'], item['work_name'], item['description'])
def create_table(self):
sql = """
create table if not exists ali_work(
id int primary key auto_increment,
categories varchar(20),
work_name varchar(50),
work_desc text
);
"""
try:
self.cursor.execute(sql)
print('表创建成功...')
except Exception as e:
print('表创建失败:', e)
def insert_work_info(self, *args):
sql = """
insert into ali_work(
id,
categories,
work_name,
work_desc) values (%s, %s, %s, %s);
"""
try:
self.cursor.execute(sql, args)
self.db.commit()
print('数据插入成功...')
except Exception as e:
print('数据插入失败:', e)
self.db.rollback()
def main(self):
self.create_table()
all_work_generator_object = self.get_work_info()
self.parse_work_info(all_work_generator_object)
ali_work = ALiWork()
ali_work.main()5.MongoDB数据库存储
MongoDB回顾
MongoDB是由C++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似JSON对象,它的字段值可以包含其他文档、数组及文档数组。在这一节中,我们就来回顾Python 3下MongoDB的存储操作。
常用命令:
查询数据库:
show dbs使用数据库:
use 库名查看集合:
show tables/show collections查询表数据:
db.集合名.find()删除表:
db.集合名.drop()
链接MongoDB
连接MongoDB时,我们需要使用PyMongo库里面的MongoClient。一般来说,传入MongoDB的IP及端口即可,其中第一个参数为地址host,第二个参数为端口port(如果不给它传递参数,默认是27017)
import pymongo # 如果是云服务的数据库 用公网IP连接
client = pymongo.MongoClient(host='localhost', port=27017)指定数据库与表
import pymongo
client = pymongo.MongoClient(host='localhost', port=27017)
collection = client['students']插入数据
对于students这个集合,新建一条学生数据,这条数据以字典形式表示:
# pip install pymongo
import pymongo
mongo_client = pymongo.MongoClient(host='localhost', port=27017)
collection = mongo_client['students']['stu_info']
# 插入单条数据
# student = {'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male'}
# result = collection.insert_one(student)
# print(result)
# 插入多条数据
student_1 = {'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male'}
student_2 = {'id': '20170202', 'name': 'Mike', 'age': 21, 'gender': 'male'}
result = collection.insert_many([student_1, student_2])
print(result)结合MongoDB采集数据入库
获取到爱奇艺视频数据信息:标题、播放地址、简介
目标地址:https://list.iqiyi.com/www/2/15-------------11-1-1-iqiyi--.html?s_source=PCW_SC
import pymongo
import requests
class AiQiYi:
def __init__(self):
self.mongo_client = pymongo.MongoClient(host='localhost', port=27017)
self.collection = self.mongo_client['py_spider']['AiQiYi']
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
'Referer': 'https://list.iqiyi.com/www/2/15-------------11-1-1-iqiyi--.html?s_source=PCW_SC'
}
self.api_url = 'https://pcw-api.iqiyi.com/search/recommend/list'
def get_movie_info(self, params):
response = requests.get(self.api_url, headers=self.headers, params=params).json()
return response
def parse_movie_info(self, response):
category_movies = response['data']['list']
for movie in category_movies:
item = dict()
item['title'] = movie['title']
item['playUrl'] = movie['playUrl']
item['description'] = movie['description']
print(item)
self.save_movie_info(item)
def save_movie_info(self, item):
self.collection.insert_one(item)
def main(self):
for page in range(1, 6):
params = {
'channel_id': '2',
'data_type': '1',
'mode': '11',
'page_id': page,
'ret_num': '48',
'session': 'c34d983f1e0c84ea7fc01dd923c9833e',
'three_category_id': '15;must',
}
info = self.get_movie_info(params)
self.parse_movie_info(info)
if __name__ == '__main__':
aqy = AiQiYi()
aqy.main()6.数据去重
在抓取数据的过程中可能因为网络原因造成爬虫程序崩溃退出,如果重新启动爬虫的话会造成数据入库重复的问题。
接下来我们使用redis来进行数据去重。
环境准备
安装
redistxtpip install redis -i https://pypi.douban.com/simple
项目需求以及思路分析
思路分析
- 首先判断当前网站上的数据是否为动态数据,如果为动态数据则使用浏览器抓包工具获取数据接口,当前接口地址如下:https://pianku.api.mgtv.com/rider/list/pcweb/v3?allowedRC=1&platform=pcweb&channelId=2&pn=1&pc=80&hudong=1&_support=10000000&kind=19&area=10&year=all&chargeInfo=a1&sort=c2
- 当获取到数据后对数据进行哈希编码,因为每一个哈希值是唯一的,所以可以利用这一特性判断数据是否重复。
- 将获取的数据存储到
mongodb数据库中,在调用保存方法之前,先调用哈希方法将数据转为哈希并保存到redis中,再判断当前获取的数据的哈希是否存在于redis数据库,如果存在则不保存,反之亦然。
代码示例
import redis
import pymongo
import hashlib
import requests
class MovieInfo:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
url = 'https://pianku.api.mgtv.com/rider/list/pcweb/v3'
def __init__(self):
self.mongo_client = pymongo.MongoClient()
self.collection = self.mongo_client['py_spider']['mg_movie_info']
self.redis_client = redis.Redis()
# 请求数据
@classmethod
def get_movie_info(cls, params):
response = requests.get(cls.url, headers=cls.headers, params=params).json()
return response
# 数据清洗以及数据结构调整
def parse_data(self, response):
movie_list = response['data']['hitDocs']
for movie in movie_list:
item = dict()
item['title'] = movie['title']
item['subtitle'] = movie['subtitle']
item['story'] = movie['story']
# 在数据清洗之后可以调用保存方法
self.save_data(item)
@staticmethod
def get_md5(value):
# md5方法只能接收字节数据
# 计算哈希值, 哈希值是唯一的, 哈希值长度为32位
md5_hash = hashlib.md5(str(value).encode('utf-8')).hexdigest()
return md5_hash
def save_data(self, item):
value = self.get_md5(item)
# 当前返回的是redis是否成功保存md5数据, 保存成功: result=1, 保存失败: result=0
result = self.redis_client.sadd('movie:filter', value)
# print(result)
if result:
self.collection.insert_one(item)
print(item)
print('保存成功...')
else:
print('数据重复...')
def main(self):
for page in range(1, 3):
params = {
"allowedRC": "1",
"platform": "pcweb",
"channelId": "2",
"pn": page,
"pc": "80",
"hudong": "1",
"_support": "10000000",
"kind": "19",
"area": "10",
"year": "all",
"chargeInfo": "a1",
"sort": "c2"
}
response = self.get_movie_info(params)
self.parse_data(response)
if __name__ == '__main__':
movie_info = MovieInfo()
movie_info.main()